缘由
公司要搭建一个内部知识库分享系统,领导推荐了一个叫WCP的项目。
因为需要自己修改一些代码,所以不能用打包好的部署包,只能自己把源码导入Eclipse修改再运行,其它都没啥问题,但就是发布文章的时候总是报一个关于Lucene的错误,是在创建索引的时候报的:
Exception in thread "main" java.lang.AbstractMethodError: org.apache.lucene.analysis.Analyzer.tokenStream(Ljava/lang/String;Ljava/io/Reader;)Lorg/apache/lucene/analysis/TokenStream;
at org.apache.lucene.analysis.Analyzer.reusableTokenStream(Analyzer.java:80)
at org.apache.lucene.index.DocInverterPerField.processFields(DocInverterPerField.java:132)
at org.apache.lucene.index.DocFieldProcessorPerThread.processDocument(DocFieldProcessorPerThread.java:276)
at org.apache.lucene.index.DocumentsWriter.updateDocument(DocumentsWriter.java:766)
at org.apache.lucene.index.IndexWriter.addDocument(IndexWriter.java:2060)
at org.apache.lucene.index.IndexWriter.addDocument(IndexWriter.java:2034)
at com.lutongnet.Test.create(Test.java:60)
at com.lutongnet.Test.main(Test.java:118)
由于对Lucene不熟,所以只能暂时屏蔽创建索引的过程,但是这样肯定影响搜索功能,有强迫症的我就是不爽。
后来下载了官网现成的war包,这个是3.2.1版的,源码的那个是3.2.0,这个丢到tomcat下面跑没有问题,所以怀疑应该是3.2.1版应该做了什么改进,但是也没有仔细对比。由于没时间没去做更进一步研究。
经过
今天抽空准备稍微学习一下Lucene,以便更好的找出问题,故意下载和wcp使用的一样的版本,lucene-core-3.6.0.jar,按照网上的例子写了一个创建索引的过程,发现没问题,然后对比wcp里面的代码,发现代码类似,唯一的不同是它用了一个叫IKAnalyzer-2012.jar的中文分词工具:
Analyzer luceneAnalyzer = new StandardAnalyzer(Version.LUCENE_36); // 自带分词工具
Analyzer ikAnalyzer = new IKAnalyzer(); // IK分词
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_36, ikAnalyzer); // 改用IK分词
但是也没问题啊,然后突发奇想百度了一下上面的错误,好家伙,貌似找到答案了,说是IK分词器和Lucene版本不匹配的问题,于是我对比了下war包版的和源码版的区别,尼玛,果然不一样,虽然jar包名字一模一样但是文件大小不一样:
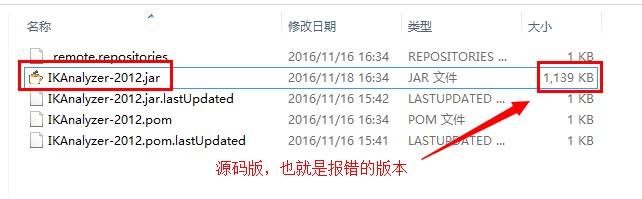

然后替换成1145kb的版本,果然不报错了!哎,此时不知道说什么好。
后来才想起来:由于作者说明没写好,刚开始发现缺少IKAnalyzer-2012.jar的时候我是自己去网上下载了一个版本,然后安装到maven本地,后来发现项目里面已经有一个了,然后我虽然重新安装了,但是不知什么原因没有替换掉,导致最后用的是那个网上下的版本!哎,一个这个问题坑了我这么久!醉了!
